The importance of HTML character encoding
W3C/WHATWG HTML5 specification states:
A character encoding declaration is required (…) even when all characters are in the ASCII range, because a character encoding is needed to process non-ASCII characters entered by the user in forms, in URLs generated by scripts, and so forth.
When the character encoding is not specified, the browser is left to determine the encoding before parsing the document. The user agent will search for character encoding declarations in the first 1024 bytes. Therefore, if you don’t set the encoding of the document neither in the Content-Type header nor using the META tag, the browser will have to wait for the first 1024 bytes and only then may attempt to auto-detect the character encoding or fallback to the user-specified default character encoding.
It’s important to specify a character set of the document as earlier as possible, otherwise the user agent will “idle” before it actually can start parsing HTML and loading other important resources (styles and scripts). This negatively impacts the page load time, especially on a slow connection or when the server flushes the early-head. The later can be completely meaningless when it’s under 1024 bytes and the character encoding of the document is not indicated.
To demonstrate this I made a simple HTTP server which flushes early-head of the document immediately and waits for a second before sending the rest of it. The early-head contains a script tag with the async attribute and a link tag to the external stylesheet.
<script src="…" async
onload="console.log({scripts: performance.now()})"></script>
<link href="…" rel="stylesheet"
onload="console.log({styles: performance.now()})">
<script>
document.addEventListener(
'DOMContentLoaded',
() => console.log({DOMContentLoaded: performance.now()})
);
</script>If the character encoding is specified, then the browser (Firefox in this particular case) begins parsing HTML immediately along with loading external resources. On the image below, you can see that the script and the stylesheet have been loaded before DOM becomes interactive.

When the character encoding is not specified, then the browser starts parsing HTML only after it gets the rest of the document (the first 1024 bytes), causing a delay in loading scripts and stylesheets.
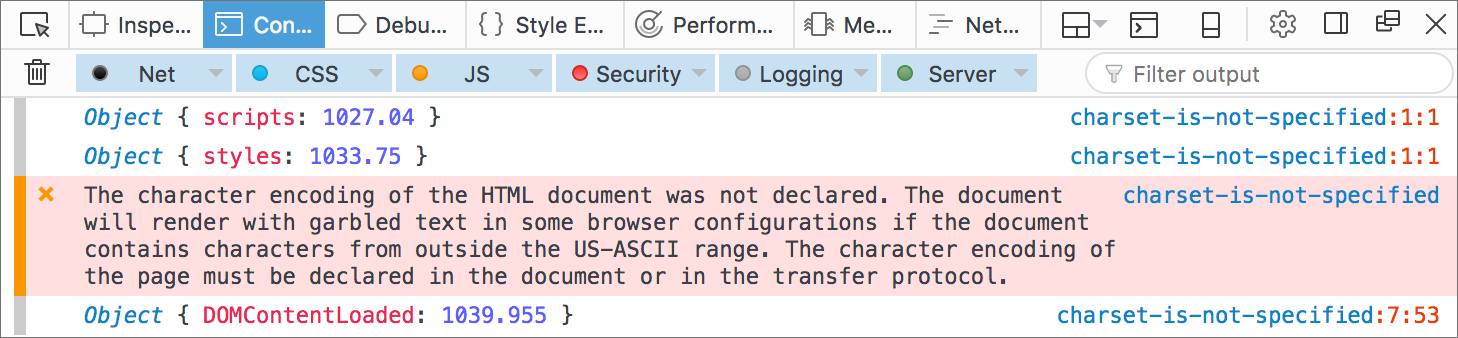
Safari shares similar to Firefox behavior. Things are quite different with Chrome and Edge, they begin parsing HTML right away even if the character encoding is not specified or incorrect.
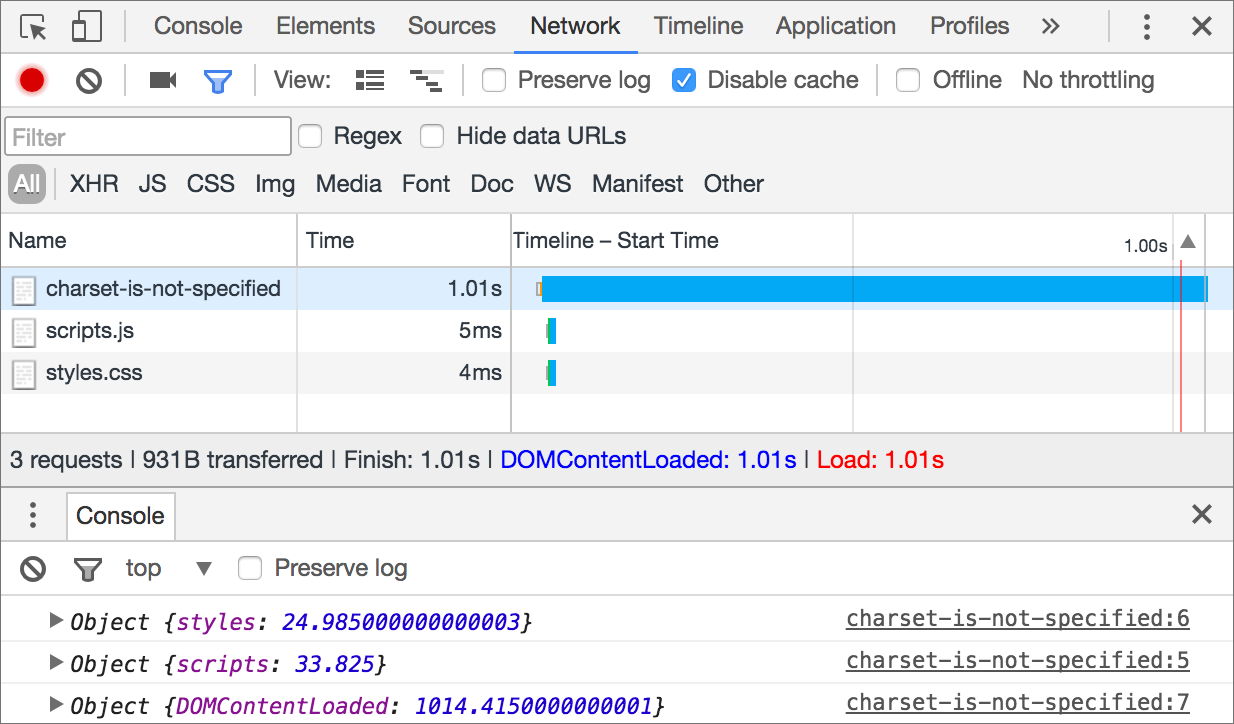
What’s incorrect encoding? HTML5 specification says that user agents must not support the CESU-8, UTF-7, BOCU-1, SCSU, EBCDIC and UTF-32 encodings. For that reason, Firefox and Safari won’t parse the document UTF-7 encoded until they get the first 1024 bytes.
On a final note, it’s important that the character set specified in the Content-Type header or META tag matches the encoding actually used for the document. If the browser detects an incorrect or mismatched encoding, it can re-parse the document with the real encoding resulting in additional delays.